Integration Overview
The foundational concepts, expected data flow, & design considerations involved with an integration.
Key Concepts
1. Overview
Agolo Entity Intelligence is a Natural Language Processing (NLP) engine designed to ingest documents and extract the key entities (people, places, things, etc.) and the key information regarding those entities from those documents. It then links and optionally adds that information to your private knowledge base. The platform enables rich downstream analytical and automation functions.
2. Key Terms
To make sense of the integration instructions and workflows in this guide, it is important to familiarize yourself with the following terms and their definitions:
- (Named) Entity - Distinct items or concepts, often representing real-world objects, like people, places, or organizations.
- Named Entity Recognition (NER) - The process of identifying and classifying named entities in a text. Agolo provides several libraries for this step of the process, but also allows customers to provide their own NER library, should they have one.
- Entity Linking - Merging or linking references to the same real-world entity from different sources.
- Entity Disambiguation - The process of using context clues to disambiguate between entities with similar names.
- Knowledge Base - The customer's private Entity Intelligence database containing both (1) any and all pre-seeded entity records, whether from public data (e.g. Wikidata) or private data (e.g. SQL database records); and (2) all the entity information extracted from any documents ingested by the system.
- Authoritative Identity- An entity that exists in the Knowledge Base that has been vetted either by a human or else by some user-defined, intelligent, automation system. All pre-seeded entities in the knowledge base are assumed to be authoritative. Authoritative Entities are also referred to as Identities.
- Ghost Identity - Any entity the engine encounters within a document that does not yet authoritatively exist in the knowledge base. While these entities and their information do get added to the Knowledge Base, ideally they would get converted into Authoritative Identities through some workflow, either via a human-in-the-loop process or some other intelligent automation process.
- Linking Confidence - Whenever an entity is encountered in a document, it is compared with existing Authoritiative & Ghost Identities in the Knowledge Base to determine its similarity, which is numerically calculated as a confidence score between 0 & 100.
- Ghost Creation Threshold - The system setting that defines the minimum Linking Confidence required for an extracted entity to be linked with a given identity record in the knowledge base. Below that threshold, the entity will not be linked to the identity in the KB and instead a Ghost Identity record will be created for it.
Understand the Entity Intelligence Data Flow
Before integrating with the Agolo Entity Intelligence platform, it is important to understand the expected data flow through the engine. Study the below diagram to understand this flow:
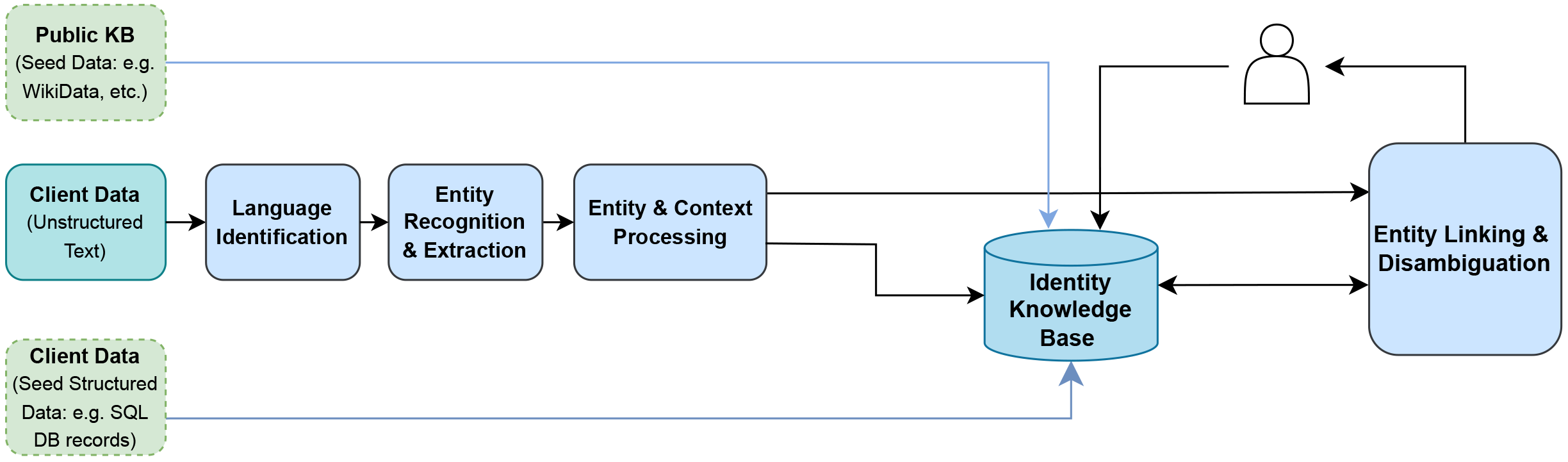
Essentially, the system is initalized by bootstrapping the knowledge base with structured data that constitutes authoritative entity (aka "identity") records. Then, the system can ingest unstructured documents, linking the entities and associated information extracted from the documents to the records that were loaded into the knowledge base where they exist or else creating new "ghost" entity records in the knowledge base if the entities don't yet exist in the knowledge base. The "ghost" entities will remain in "ghost" status until a human (or some other intelligent agent) reviews and either promotes them to being authoritative or takes some other action on them.
Design the Integration
With the Key Concepts and the Data Flow in mind, the integration can be designed.
Key Considerations
- Pre-seeding the Knowledge Base with Identities vs Starting from Scratch?
- Should the Knowledge Base be pre-seeded or start clean?
- If pre-seeding, what authoritative entity (aka "identity") data is available and relevant to use for the use case?
- If pre-seeding, should the seed data be only public data, only private data, or a combination of both?
- Tolerance for False Positives vs False Negatives?
- False Positives = Incorrectly associating an extracted Entity with an existing Identity in the Knowledge Base; this happens with the Ghost Creation Threshold is set too low.
- False Negatives = Incorrectly missing that a reference of Entity from a document should have been associated with an existing record in the Knowledge Base; this happens with the Ghost Creation Threshold is set too high.
- Tuning the Ghost Creation Threshold value for a given use case involves finding the right balance between False Positives & False Negatives based on the types of characteristic data sources that will be encountered in the integration.
- How will extracted & associated Entity information be leveraged?
- Will automated systems be connected to the platform or will it be human analysts?
- Will the system have a user interface?
- What will the unstructured data entering the system look like?
- Will it be a consistent format?
- Will it change over time?
- How will identity knowledge base curation happen?
- The Agolo system operates best when there is periodic human curation of the knowledge base, e.g. promoting Ghost Identities to Authoritative Identities, splitting identity information that was incorrectly merged via a false positive link, or on the flip side, merging identity information that was incorrectly siloed via a false negative misassociation. How can the integration be designed to make these curation workflows as easy as possible.
Basic Flow
- Upload Authoritative Identity Records - The Knowledge Base needs access to Authoritative Identity records - this is typically an initial dump followed by continuous additions and updates.
- Upload Documents for Processing - Documents can either be added in bulk or can be added incrementally as received.
- Validate the Processing & Curate the Knowledge Base with Human-in-the-Loop Analysis - Exploited Documents should be reviewed and any mistakes corrected through manual curation as soon as possible. tip
Manual curation early in the exploitation process can prevent misassociated information from accumulating and will generally produce better subsequent autonomous system results.
- Integrate Downstream Applications - The disambiguated database is a powerhouse in providing useful consolidated information about entities. It can be tied into analyst applications, search interfaces, as well as data visualization software, and more.
In the next section, you will find details for how to actually implement this flow, along with code examples.